
Hash算法之MD5算法
Hash 函数结构
Hash 函数的一般结构如图6-1所示,称为Hash 函数迭代结构,也称为MD 结构。它由 Merkle 和 Damgard 分别独立提出,包括 MD5,SHA1 等目前所广泛使用的大多数 Hash 函数都采用这种结构。MD 结构将输人消息分为L个固定长度的分组,每一分组长为b位,最后一个分组包含输入消息的总长度,若最后一个分组不足b位时,需要将其填充为b位。由于输人包含消息的长度,所以攻击者必须找出具有相同散列值且长度相等的两条消息,或者找出两条长度不等但加入消息长度后散列值相同的消息,从而增加了攻击的难度。
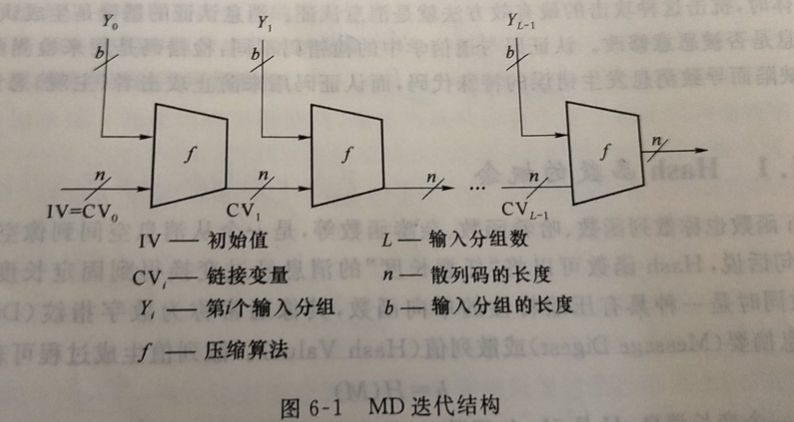
迭代结构包含一个压缩函数f。压缩函数f有两个输入:一个是前一次迭代的n 位输出,称为链接变量;另一个是消息的b位分组,并产生一个 n 位的输出。因为一般来说消息分组长度b大于输出长度n,因此称之为压缩函数。第一次迭代输入的链接变量又称为初值变量,由具体算法指定,最后一次迭代的输出即为散列值。
MD5 算法
MD5 算法是美国麻省理工学院著名密码学家 Rivest 设计的,MD(Message Digest)是消息摘要的意思。Rivest 于 1992 年向 IETF 提交的 RFC1321 中对 MD5作了详尽的述 MD5 是在MD2、MD3和MD4 基础上发展而来的,尤其在 MD4 上增加了 Safety-Belts,所以MD5 又被称为是“系有安全带的 MD4”,它虽然比MD4 要稍慢一些,但更为安全。
1. MD5 算法描述
MD5算法的输人是长度小于$2^{64}$比特的消息,输出为 128 比特的消息摘要。输人消息以512 比特的分组为单位处理,其流程如下:
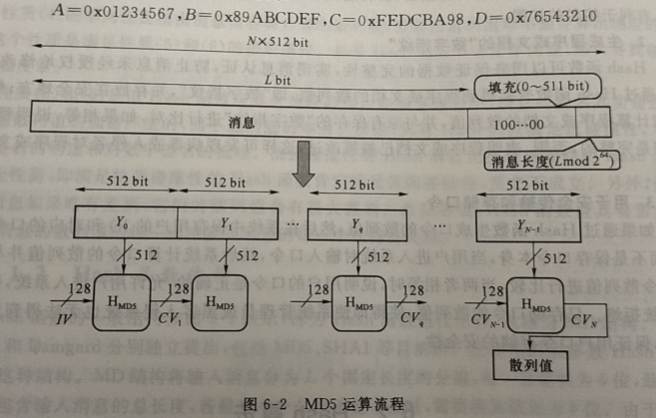
L为消息的长度;N 为消息扩充后分组个数:$Y_i(0 \leq i \leq N-1)$代表一个分组;IV表示初始链接变量,A、B、C、D是4个32位的寄存器;$CV_i$是链接变量,即是第i个分组处理单元的输出,也是第 i+1 个分组处理单元的输人,最后单元的输出$ CV_N$ 即是消息的散列值。
主要流程概括起来便是:消息预处理, 初始化缓冲区, 循环哈希,下面会依次介绍
2.MD5 具体流程
1. 消息预处理
-
附加补充位
在长度为
K bits的原始消息数据尾部填充长度为P bits的标识100…0,$1 \leq P \leq 512 $(即至少要填充1个bit),使得填充后的消息位数为:$K + P \equiv 448 (mod 512).$注意到当 $K \equiv 448 (mod 512) $时,需要 P= 512.
-
附加信息
原始消息长度(注意是长度)以 64 比特表示附加在填充结果的后面,最后得到一个长度位数为 $K + P + 64 \equiv 0 (mod 512) $的消息。
原因: 增加攻击者伪造明文的难度. 伪造信息的长度必需要与原文长度相等(其实是同余)
将消息长度 $Length(M)(mod2^{64})$ 以小端序的形式附加到第一步预留的 64-bit 空间中.
后面会讲小端序和大端序
按以上步骤处理完消息之后, 将最后的得到的消息结果分割成 L 个 512-bit 分组:$Y_0, Y_1, \ldots ,Y_{L - 1}$
分组结果按 32-bit 一组, 被分为 16 组字(Word) (512 = 32 * 16),$M_0[0],M_0[1],\ldots,M_0[15],M_1[0]\ldots, M_{L - 1}[16]$,在本文中被记作 $M_i[j]$,其中j表示字的组数.
2.初始化缓冲区
算法使用 128-bit 的缓冲区存放中间结果和最终哈希值, 128-bit 可以看做 4 组32-bit字所占的比特位(128 = 4 * 32)
被记作 $Buffer_A,Buffer_B,Buffer_C,Buffer_D$. 每个缓冲区都以小端序的方式存储数据. 将 4 块 Buffer 组合起来记为链接向量$ CV_i$
$$
CV_i=CV_{i−1}
$$
$CV_0$ 被规定为常量, 如下表格所示.(在最上面的流程图里面现实的$IV$),即 A、B、C、D 的值分别为 0x67452301,0xEFCDAB89,0x98BADCFE,0x10325476)
每一个变量给出的数值是高字节存于内存低地址,低字节存于内存高地址,即大端字节序
注意一个存储单元可以存储两位,当然也是一个字
| 字节序 | 存储内容 |
|---|---|
| 小端序 | Buffer[4] = {0x01234567, 0x89ABCDEF, 0xFEDCBA98, 0x76543210}; |
| 大端序 | Buffer[4] = {0x67452301, 0xEFCDAB89, 0x98BADCFE, 0x10325476}; |
3.循环哈希
调用 $H_{MD5}(M_i,CV_i)$ 函数对每组消息分组进行哈希计算.
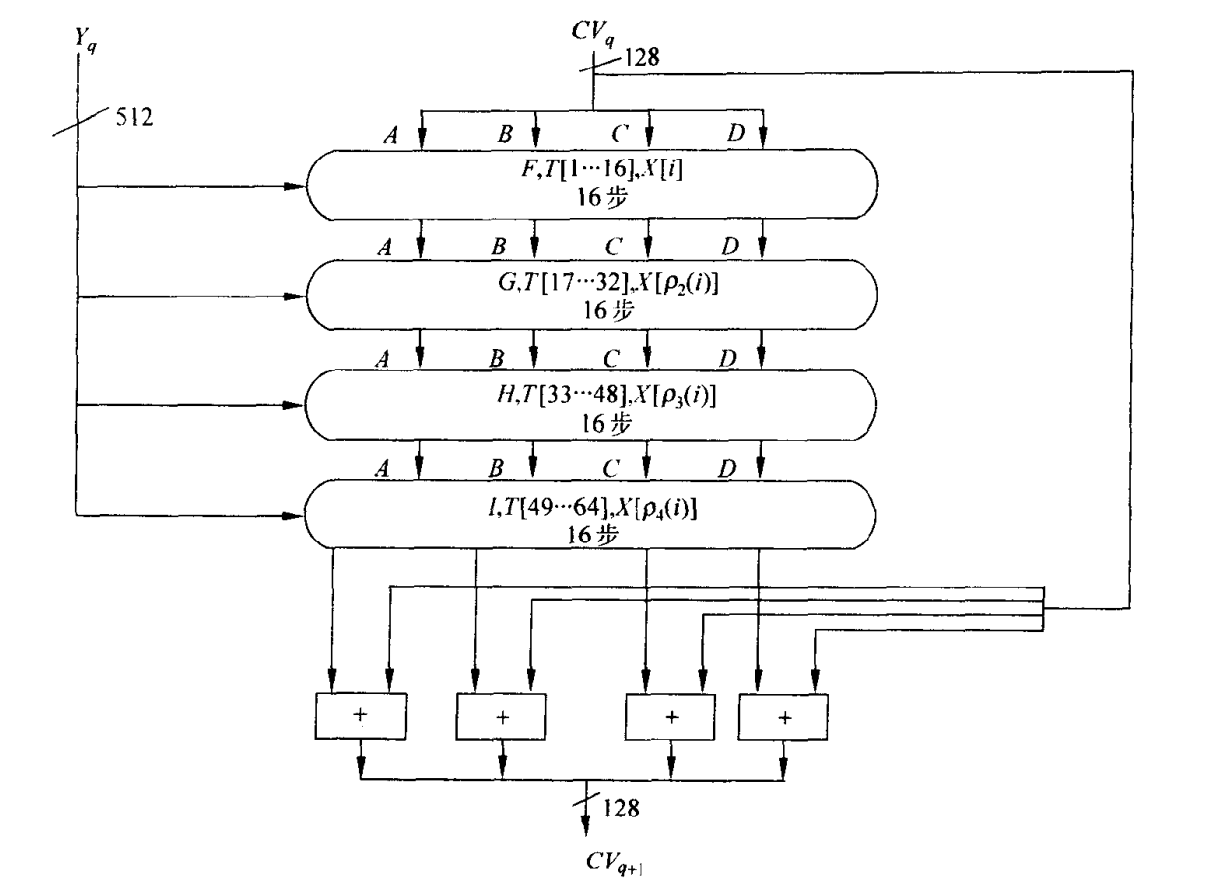
每一次$ H_{MD5}()$ 中有 4 轮结构相同的逻辑函数, 不同轮次间的唯一区别是参与计算的逻辑函数不同, 分别表示为 F、G、H、I.
下面步函数会介绍 F、G、H、I
此外, $H_{MD5}()$ 还有一个常数表 T, 常数表 T 为定义为 $T[i]=[2^{32} \times abs(sin(i))]=[4294967296 \times abs(sin(i))],1 \leq i \leq 64$ (前 32-bit 小数.) (i 是弧度),如$T[28]=[4294967296 \times abs(sin(28))] \approx [1163531501.079 3967247]$,然后其整数部分转化为十六进制$T[28]=(1163531501){10}=(455A14ED){16}$。T[i]是一个伪随机的常数,可以消除输入数据的规律性,其详细取值见表 6-1。

1 | //常熟T[i](i = 1,...,64) |
在本文中把 $H_{MD5}$ 的轮函数记为 $R(M_i,Buffer,T[],function_i())$. 其中, 轮函数每次调用是都会读取缓存区中的数据. 而且不同轮次之间所调用的逻辑函数也是不一样的. 此外, 每一次调用轮函数会用到不同 16 组 T 元素(对应轮函数内部的中 16 次迭代).
$H_{MD5}()$ 完成第四轮轮函数处理之后, 将得到的结果和输入的$ CVi$按字(每 32-bit) 分组按位加. 得到最终输出结果$ CV{i+1}$.
3.轮函数(压缩函数)的具体实现
MD5算法的分组处理(压缩函数)与分组密码的分组处理相似,如图 6-3 所示。它由4轮组成,512比特的消息分组M被均分为16个子分组(每个子分组为 32比特)参与每轮16步函数运算,即每轮包括16 个步骤。每步的输人是4个 32比特的链接变量和一个32比特的消息子分组,输出为32位值。经过4轮共 64 步后,得到的个存器值分别与输人链接变量进行模加,即得到此次分组处理的输出链接变量。
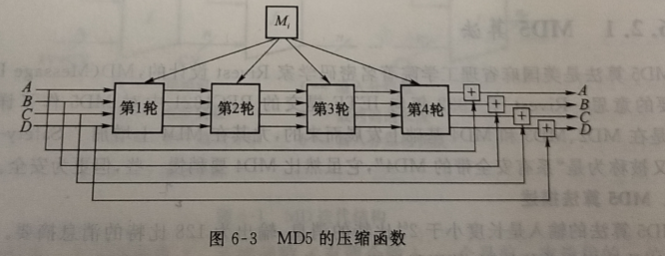
4 轮操作开始前,先将前一分组的链接变量(A、BC 和 D 的值)复制到另外 4 个备用记录单元AA、BB、CC和DD,以便执行最后的模加运算。
轮函数每次调用内部有 16 次迭代计算, 将轮函数当前迭代的次数记作 i
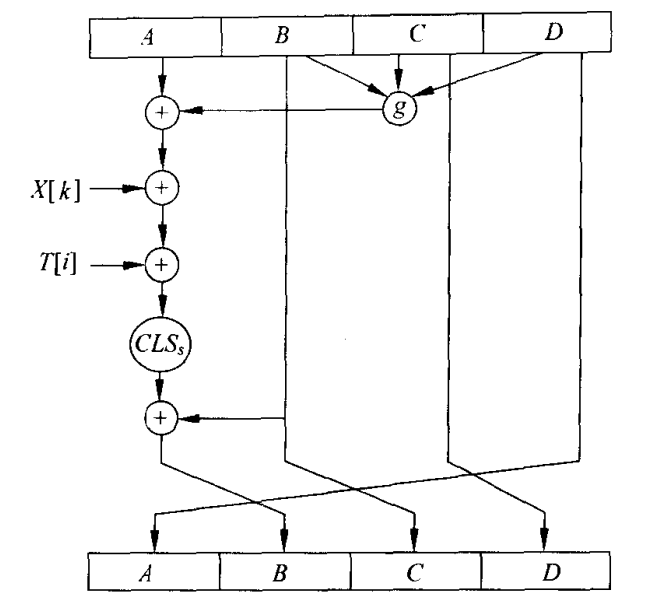
读取缓冲区中的数据, 将缓冲区按字 32-bit 分为4组, 记作 A、B、C、D
-
第一步
BCD 暂时不动, A 有以下 x 层计算:
-
$A+Logic_Function_{轮数}(B,C,D)$
$F(b,c,d)=(b∧c)∨(\overline b∧d)$
$G(b,c,d)=(b∧d)∨(c∧\overline d)$
$H(b,c,d)=b⊕c⊕d$
$I(b,c,d)=c⊕(b∨\overline d)$
-
$A+M_i[k]$ (k 受到当前轮数以及迭代次数 i 的影响)
-
$A+T[i]$ (受到输入影响, 与当前轮数有关)
$ρ_1(i)=i$
$ρ_2(i)=(1+5i)mod16$
$ρ_3(i)=(5+3i)mod16$
$ρ_4(i)=7imod16$
-
A 循环(注意是循环)左移 s 位 (s 由一个常量表给出)
s[ 1…16] = { 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22 }
s[17…32] = { 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20 }
s[33…48] = { 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23 }
s[49…64] = { 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21 } -
A + B
-
-
第二步
对缓冲区中的四个字按字右循环位移 1 个字 即新的缓冲区$ Buffer′=D′||A′||B′||C′$
也就是说, 一组消息的压缩要经过这样的过程:
-
轮次一(F)
1
2
3
4
5/* [abcd k s i] a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
[ABCD 0 7 1][DABC 1 12 2][CDAB 2 17 3][BCDA 3 22 4]
[ABCD 4 7 5][DABC 5 12 6][CDAB 6 17 7][BCDA 7 22 8]
[ABCD 8 7 9][DABC 9 12 10][CDAB 10 17 11][BCDA 11 22 12]
[ABCD 12 7 13][DABC 13 12 14][CDAB 14 17 15][BCDA 15 22 16] -
轮次二(G)
1
2
3
4
5/* [abcd k s i] a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
[ABCD 1 5 17][DABC 6 9 18][CDAB 11 14 19][BCDA 0 20 20]
[ABCD 5 5 21][DABC 10 9 22][CDAB 15 14 23][BCDA 4 20 24]
[ABCD 9 5 25][DABC 14 9 26][CDAB 3 14 27][BCDA 8 20 28]
[ABCD 13 5 29][DABC 2 9 30][CDAB 7 14 31][BCDA 12 20 32] -
轮次三(H)
1
2
3
4
5/* [abcd k s i] a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
[ABCD 5 4 33][DABC 8 11 34][CDAB 11 16 35][BCDA 14 23 36]
[ABCD 1 4 37][DABC 4 11 38][CDAB 7 16 39][BCDA 10 23 40]
[ABCD 13 4 41][DABC 0 11 42][CDAB 3 16 43][BCDA 6 23 44]
[ABCD 9 4 45][DABC 12 11 46][CDAB 15 16 47][BCDA 2 23 48] -
轮次四 (I)
1
2
3
4
5/* [abcd k s i] a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
[ABCD 0 6 49][DABC 7 10 50][CDAB 14 15 51][BCDA 5 21 52]
[ABCD 12 6 53][DABC 3 10 54][CDAB 10 15 55][BCDA 1 21 56]
[ABCD 8 6 57][DABC 15 10 58][CDAB 6 15 59][BCDA 13 21 60]
[ABCD 4 6 61][DABC 11 10 62][CDAB 2 15 63][BCDA 9 21 64]
4. 案例
用 MD5 算法处理 ASCII 码序列“iscbupt”
我是手机拍的,懒得手打了,请见谅(❁´◡`❁)
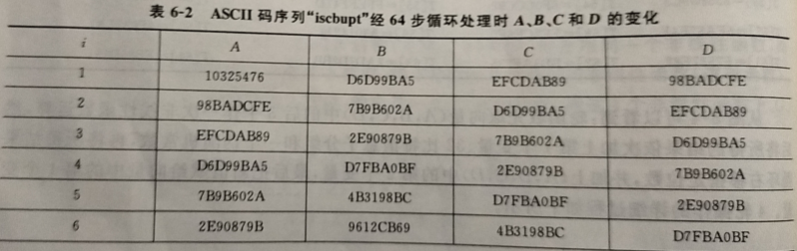
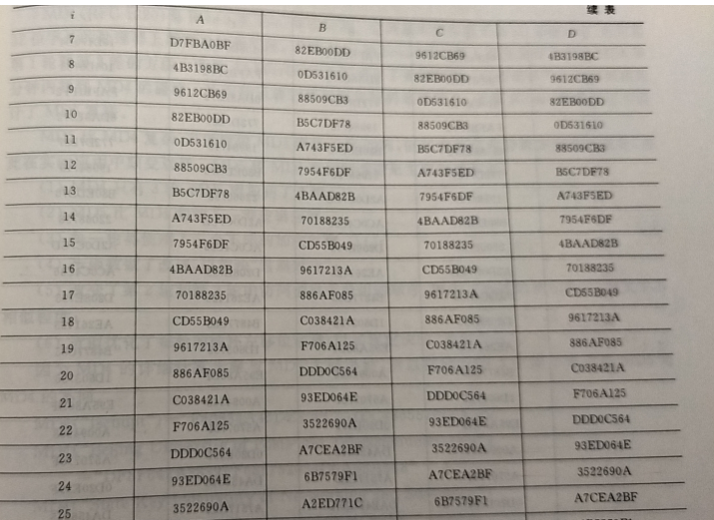
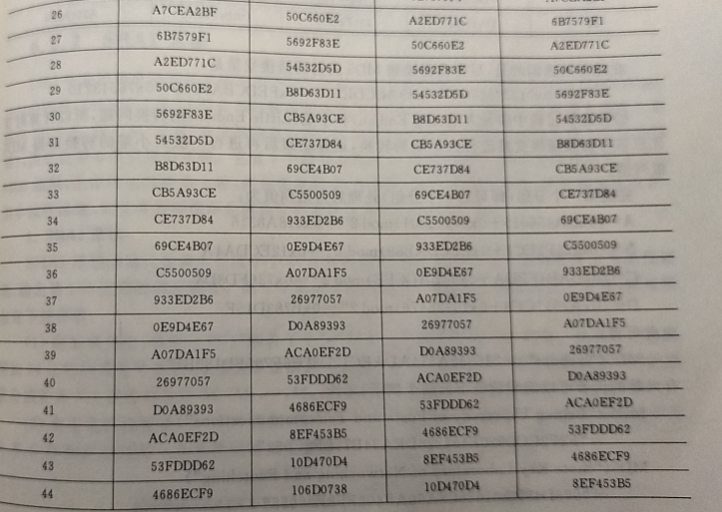
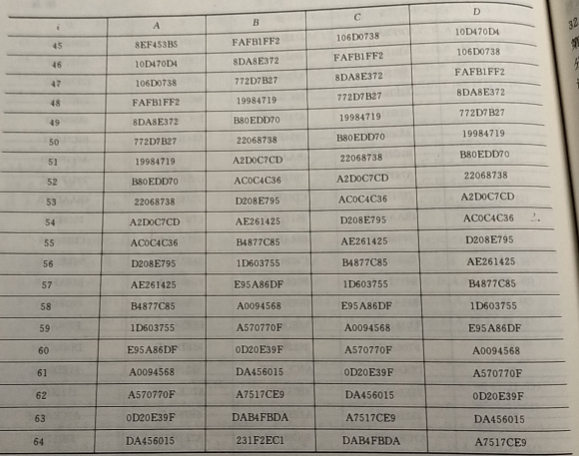
在此特别强调的是,尽管前面提到 MD5的初始链接变量是:
A=0x01234567,B=0x89ABCDEF,C=0xFEDCBA98,D=0x76543210
但在运算过程中涉及大端(Big Endian)和小端 Little Endian)的转换问题,所以计算时首先应该将初始链接变量进行大小端的转换,运算结束后再进行一次大小端的转换即得 MD5 散列值。
完成第一个分组(即最后一个分组)处理后得散列值为:
$A=(0xDA456015+0x67452301)mod 2^{23}=0x418A8316$
$B=(0x231F2EC1+0xEFCDAB89)mod 2^{32}=0x12ECDA4A$
$C=(0xDAB4FBDA+0x98BADCFE)mod 2^{32} = 0x736FD8D8$
$D=(0xA7517CE9+0x10325476)mod2^{32}=0xB783D15F$
由此可得:
MD5(“iscbupt”)=“16838A414ADAEC12D8D86F735FD183B7”
5.代码实现
大量注释来袭 o((>ω< ))o
还有就是注意一个字就是 8bit,注意有地方看不懂是不是没换算的问题,如果还是不懂请评论留眼
1 |
|
结果
1 | ----------------- MD5 ----------------- |
